Introduction
Background
Apache Lucene.NET is a C# port of Java based Apache Lucene. Apache Lucene has a huge following and is used directly or indirectly to power search by many companies you probably know including Amazon, Twitter, LinkedIn, Netflix, Salesforce, SAS, and Microsoft Power BI.
Apache Lucene is the core search library used by popular open source search servers like Apache Solr, ElasticSearch and OpenSearch. The reason Apache Lucene is so widely used is because it's extremely powerful and can index large amounts of data quickly -- think 100s of GB/Hours. And it can perform full text search on that data in sub-second time. And unlike traditional SQL databases, it's data engine is optimized for full text search.
The codebase for Apache Lucene is very mature. In March 2020, the open source project celebrated its 20th birthday. You can scroll through the years and see the major Apache Lucene milestones.
Apache Lucene.NET 4.8 is an open source project whose aim is to be a line by line c# port of java based Apache Lucene 4.8. This port makes the power of Lucene available to all .NET developers. And makes it easy for them to contribute to the project or customize it since it's pure C#.
Currently Lucene.NET 4.8 is in Beta but it is extremely stable and many developers already use it in production. It has far more features than Lucene.NET 3.03 and has much better unit test coverage than the older version. Lucene.NET has more than 7800+ passing unit tests. This test coverage is what makes Lucene.NET so stable.
Evolution of Lucene
Porting Lucene from java to C# is a huge undertaking. There are over 644K lines of code not counting outside dependencies. This is why only a few specific versions have been ported. The prior Lucene.NET release was version 3.0.3 and the current release (which receives all the focus) is Lucene.NET 4.8. Version 4.8 is now in late Beta and, as I already mentioned, is used in production by many developers.
{kind=link}
You might be aware that Java Lucene is at version 9.x. But don't be misled by the number. The step up in features between 3.x and 4.x was the biggest in Lucene's history and after that it was followed by many smaller releases. So the reality is that Lucene.NET 4.8 contains the vast majority of features found in Java Lucene 9.x and in fact Lucene 4.x is more similar to Lucene 9.x than to Lucene 3.x. If you'd like to dive deeper into this topic, Lucene.NET 4.8 vs Java Lucene 9.x is a community written article that covers it in more detail.
Lucene.NET is Multi-Platform
Lucene.NET 4.8 runs everywhere .NET runs: Windows, Unix or Mac. And as a library it can be used to power search in desktop applications, websites, mobile apps (iOS or Android) or even on IoT devices like the Raspberry Pi. And because it's licensed under the permissive Apache 2.0 license it's typically considered suitable for both commercial and non-commercial use.
Lucene's LSM Inspired Architecture
At this early stage of your journey it's probably good to cover a few things about how Lucene stores data. We are just going to hit the highlights here because it's a deep topic.
Lucene and hence Lucene.NET stores data in immutable "segments." Segments are made of multiple files. Segments automatically get merged together to form new bigger segments and then the old segments are typically deleted by the merge process. This approach is based on what is called a Log Structured Merge (LSM) design.
LSM has become the defacto standard for NoSql databases and is used not only by Lucene but also by Google BigTable, Apache HBase, Apache Cassandra and many others. The details of each implementation vary as does the number and types of files used. So let's take a look at what those files might look like for a Lucene.NET index.
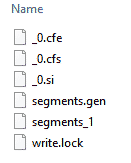
Here is an example of Lucene.NET's files for a brand new index with one segment:
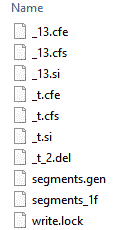
Here is a two segment example that has gone through merges many times:
Important Lucene Concepts
Documents and Fields
Lucene stores document and documents are comprised of fields. The fields can be a variety of types like Text, string or Int32.
Documents may have as many fields as you like. There is no concept of schema and documents don't need to all have the same fields. When searching you can search any field and it will only return documents which have that field and where the data in that field matches the specified search criteria.
Writing and Reading Documents
Documents are written via an IndexWriter and read via an IndexReader. Although in practice we often use an IndexSearcher (which wraps an IndexReader) for searching and reading documents.
Lucene Directories
We already mentioned that the data is stored in segments. Those segments can be stored via different classes that inherit from Lucene.Net.Store.Directory. Some of those classes, like FSDirectory store to your local file system, other can store elsewhere. For example a RAMDirectory can be useful for unit tests as it stores the segments in RAM. So one of the things that we must provide an IndexWriter is an instance of a Lucene.Net.Store.Directory that is the type of directory we want to work with.
How the Pieces Fit Together
The diagram below provides a birds eye view of how the various parts of the system work together. It makes it easier to conceptualize the parts of Lucene that we have been talking about. It might be good idea to keep this diagram in mind when you work through the tutorial examples and review the code provided there.

* In the diagram above "Files" is in quotes because if you are using a RAMDirectory, say for testing, then there will be no physical file, but rather their representation will be in memory only.
Wrapping Up
I hope this introduction has helped you to understand a bit about Lucene.NET. The information we have covered so far should give you a bit of a foundation to work from as you work through the tutorial examples and then dig deeper into the Lucene.NET Documentation and Learning Resources.